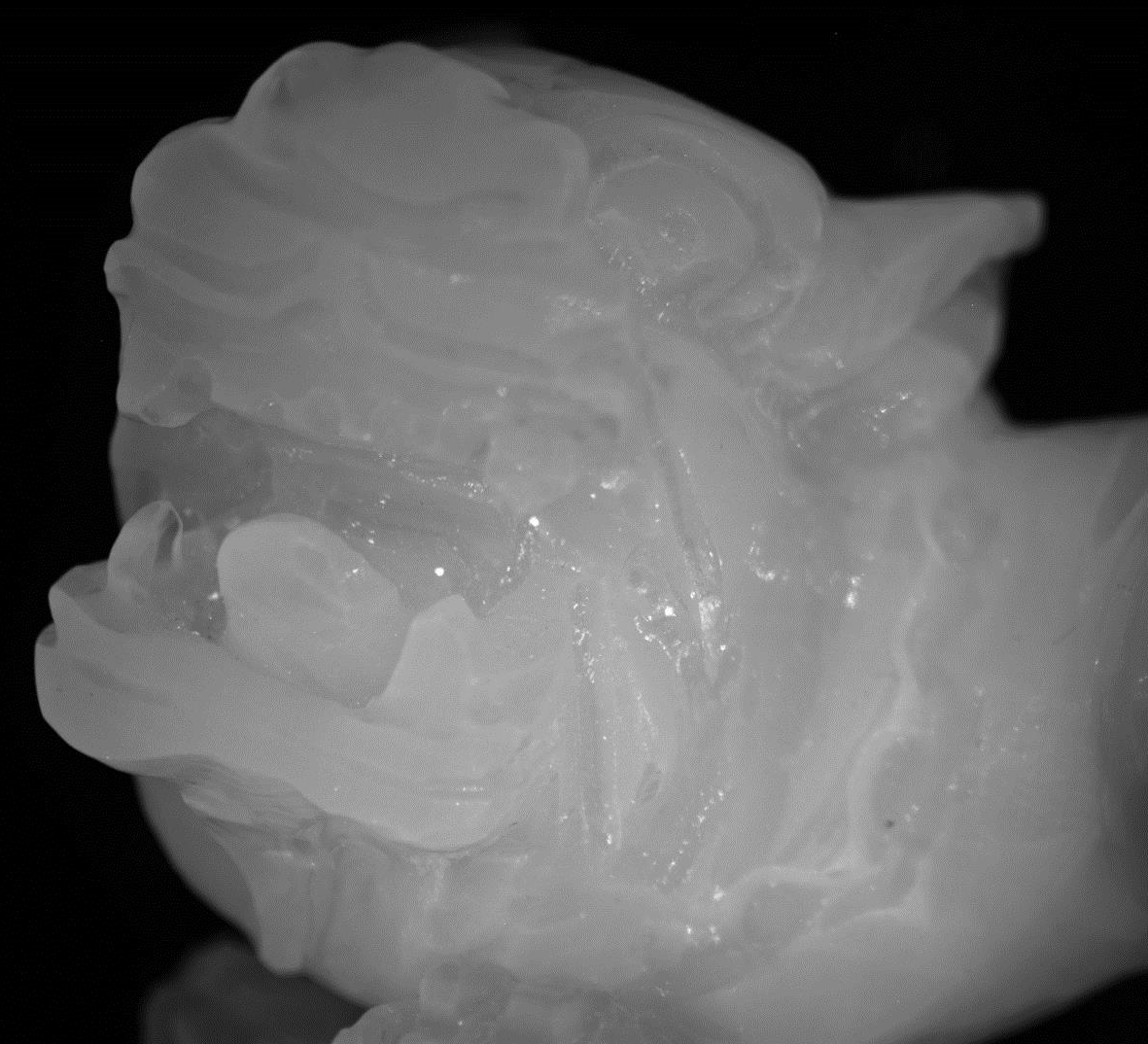
Computational Photography
Computational photography is the convergence of computer graphics, computer vision, optics and imaging. Its role is to overcome the limitations of traditional cameras, by combining imaging and computation to enable new and enhanced ways of capturing, representing, and interacting with the physical world. This advanced undergraduate course provides a comprehensive overview of the state of the art in computational photography. At the start of the course, we will study modern image processing pipelines, including those encountered on mobile phone and DSLR cameras, and advanced image and video editing algorithms. Then we will continue to learn about the physical and computational aspects of tasks such as 3D scanning, coded photography, lightfield imaging, time-of-flight imaging, VR/AR displays, and computational light transport. Near the end of the course, we will discuss active research topics, such as creating cameras that capture video at the speed of light, cameras that look around walls, or cameras that can see below skin.
Course Website →
Physics-based Rendering
This course is an introduction to physics-based rendering at the advanced undergraduate and introductory graduate level. During the course, we will cover fundamentals of light transport, including topics such as the rendering and radiative transfer equation, light transport operators, path integral formulations, and approximations such as diffusion and single scattering. Additionally, we will discuss state-of-the-art models for illumination, surface and volumetric scattering, and sensors. Finally, we will use these theoretical foundations to develop Monte Carlo algorithms and sampling techniques for efficiently simulating physically-accurate images. Towards the end of the course, we will look at advanced topics such as rendering wave optics, neural rendering, and differentiable rendering.
Course Website →
Computer Vision
This course provides a comprehensive introduction to computer vision. Major topics include image processing, detection and recognition, geometry-based and physics-based vision and video analysis. Students will learn basic concepts of computer vision as well as hands on experience to solve real-life vision problems.
Course Website →
Computer Vision
This course introduces the fundamental techniques used in computer vision, that is, the analysis of patterns in visual images to reconstruct and understand the objects and scenes that generated them. Topics covered include image processing basics, Hough Transforms, feature detection, feature descriptors, image representations, image classification and object detection. We will also cover camera geometry, multi-view geometry, stereo, 3D reconstruction from images, optical flow, motion analysis and tracking. Version B of 16-720 is intended for students with prior knowledge of computer vision and prior exposure to machine learning. Undergraduate students should take 16-385 which is the undergraduate version of the class.
Course Website →
Computer Vision
This course introduces the fundamental techniques used in computer vision, that is, the analysis of patterns in visual images to reconstruct and understand the objects and scenes that generated them. The first third of the course covers low-level image processing, including filtering, warping, image descriptors, and correspondence matching. The second third of the course covers geometry and 3D motion, including image formation, camera models, optical flow, stereo, and structure from motion. The last third of the course covers pattern recognition including deep learning, convolutional neural networks. Additional topics include radiometry, color, and photometric stereo. Prerequisites include linear algebra, probabiliity, and calculus. Courses related to 16-720A include 16-385 and 16-720B. Undergraduates should take 16-385, which serves as the undergraduate version of this course). Graduate students with little exposure to computer vision should take 16-720A, which serves as the introductory graduate version of this course. Graduate students with prior exposure to computer vision should take 16-720B, which serves as the advanced version of this course.
Course Website →
Learning-Based Image Synthesis
This course introduces machine learning methods for image and video synthesis. The objectives of synthesis research vary from modeling statistical distributions of visual data, through realistic picture-perfect recreations of the world in graphics, and all the way to providing interactive tools for artistic expression. Key machine learning algorithms will be presented, ranging from classical learning methods (e.g., nearest neighbor, PCA) to deep learning models (e.g., ConvNets, NeRF, deep generative models, including GANs, VAEs, autoregressive models, and diffusion models). Finally, we will discuss image and video forensics methods for detecting synthetic content. Students will learn to build practical applications and create new visual effects using their own photos and videos.
Course Website →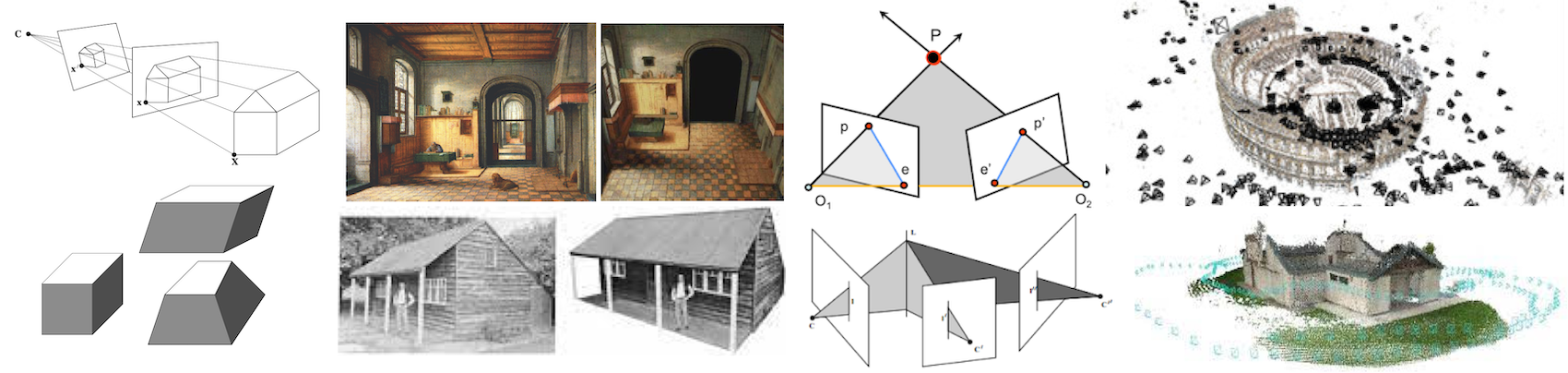
Geometry-based Methods in Vision
The course focuses on the geometric aspects of computer vision: The geometry of image formation and its use for 3D reconstruction and calibration. The objective of the course is to introduce the formal tools and results that are necessary for developing multi-view reconstruction algorithms. The fundamental tools introduced study affine and projective geometry, which are essential to the development of image formation models. These tools are then used to develop formal models of geometric image formation for a single view (camera model), two views (fundamental matrix), and three views (trifocal tensor); 3D reconstruction from multiple images; auto-calibration; and learning based methods.
Course Website →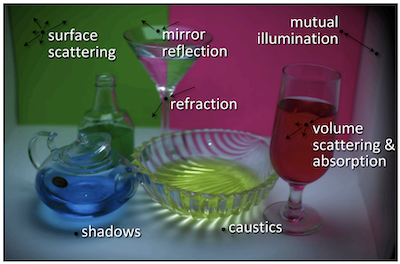
Physics based Methods in Vision
Everyday, we observe an extraordinary array of light and color phenomena around us, ranging from the dazzling effects of the atmosphere, the complex appearances of surfaces and materials, and underwater scenarios. For a long time, artists, scientists, and photographers have been fascinated by these effects, and have focused their attention on capturing and understanding these phenomena. In this course, we take a computational approach to modeling and analyzing these phenomena, which we collectively call "visual appearance". The first half of the course focuses on the physical fundamentals of visual appearance, while the second half of the course focuses on algorithms and applications in a variety of fields such as computer vision, graphics and remote sensing and technologies such as underwater and aerial imaging. This course unifies concepts usually learnt in physical sciences and their application in imaging sciences. Students attending this course will learn about the fundamental building blocks that describe visual appearance, and recent academic papers on a variety of physics-based methods that measure, process, and analyze visual information from the real world.
Course Website →
Visual Learning and Recognition
This graduate-level computer vision course focuses on representation and reasoning for large amounts of data (images, videos, and associated tags, text, GPS locations, etc.) toward the ultimate goal of understanding the visual world surrounding us. We will be reading an eclectic mix of classic and recent papers on topics including Theories of Perception, Mid-level Vision (Grouping, Segmentation, Poses), Object and Scene Recognition, 3D Scene Understanding, Action Recognition, Contextual Reasoning, Joint Language and Vision Models, Deep Generative Models, etc. We will be covering a wide range of supervised, semi-supervised and unsupervised approaches for each of the topics above.
Course Website →
Learning for 3D Vision
Any autonomous agent we develop must perceive and act in a 3D world. The ability to infer, model, and utilize 3D representations is therefore of central importance in AI, with applications ranging from robotic manipulation and self-driving to virtual reality and image manipulation. While 3D understanding has been a longstanding goal in computer vision, it has witnessed several impressive advances due to the rapid recent progress in (deep) learning techniques. The goal of this course is to explore this confluence of 3D Vision and Learning-based methods.
Course Website →
Robot Localization and Mapping
This course focuses on the optimization aspects of state estimation, localization, and mapping. Localization and mapping are fundamental capabilities for mobile robots operating in the real world. Even more challenging than these individual problems is their combination: simultaneous localization and mapping (SLAM). Robust and scalable solutions are needed that can handle the uncertainty inherent in sensor measurements, while providing localization and map estimates in real-time. We will investigate suitable efficient probabilistic inference algorithms at the intersection of linear algebra and probabilistic graphical models. We will also explore some state-of-the-art systems.
Course Website →