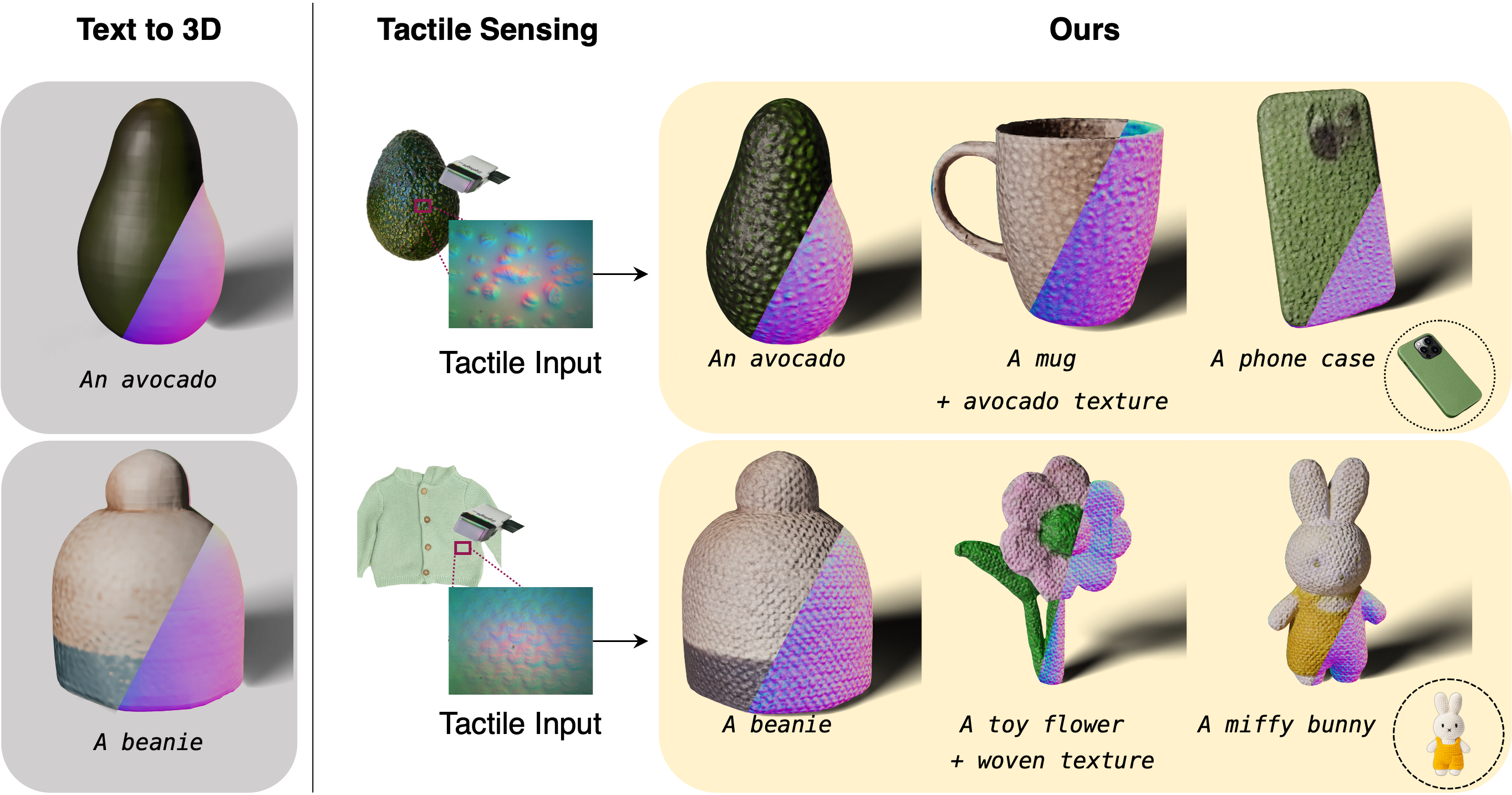
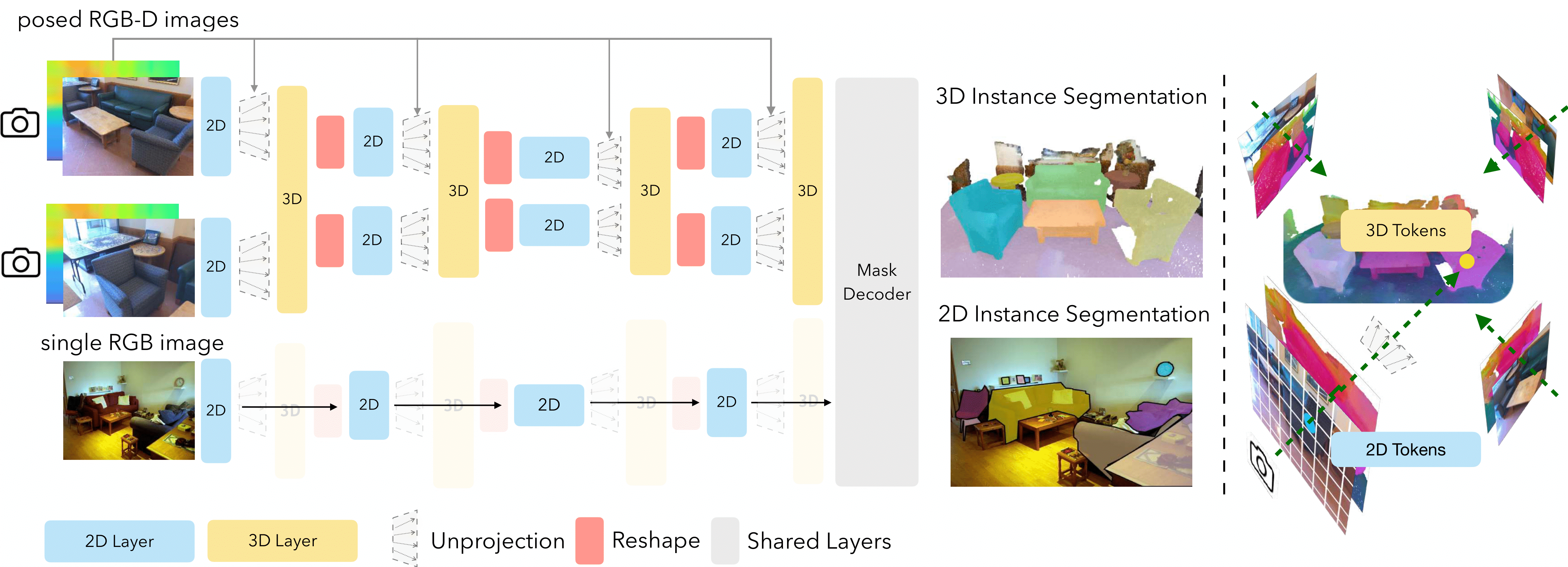
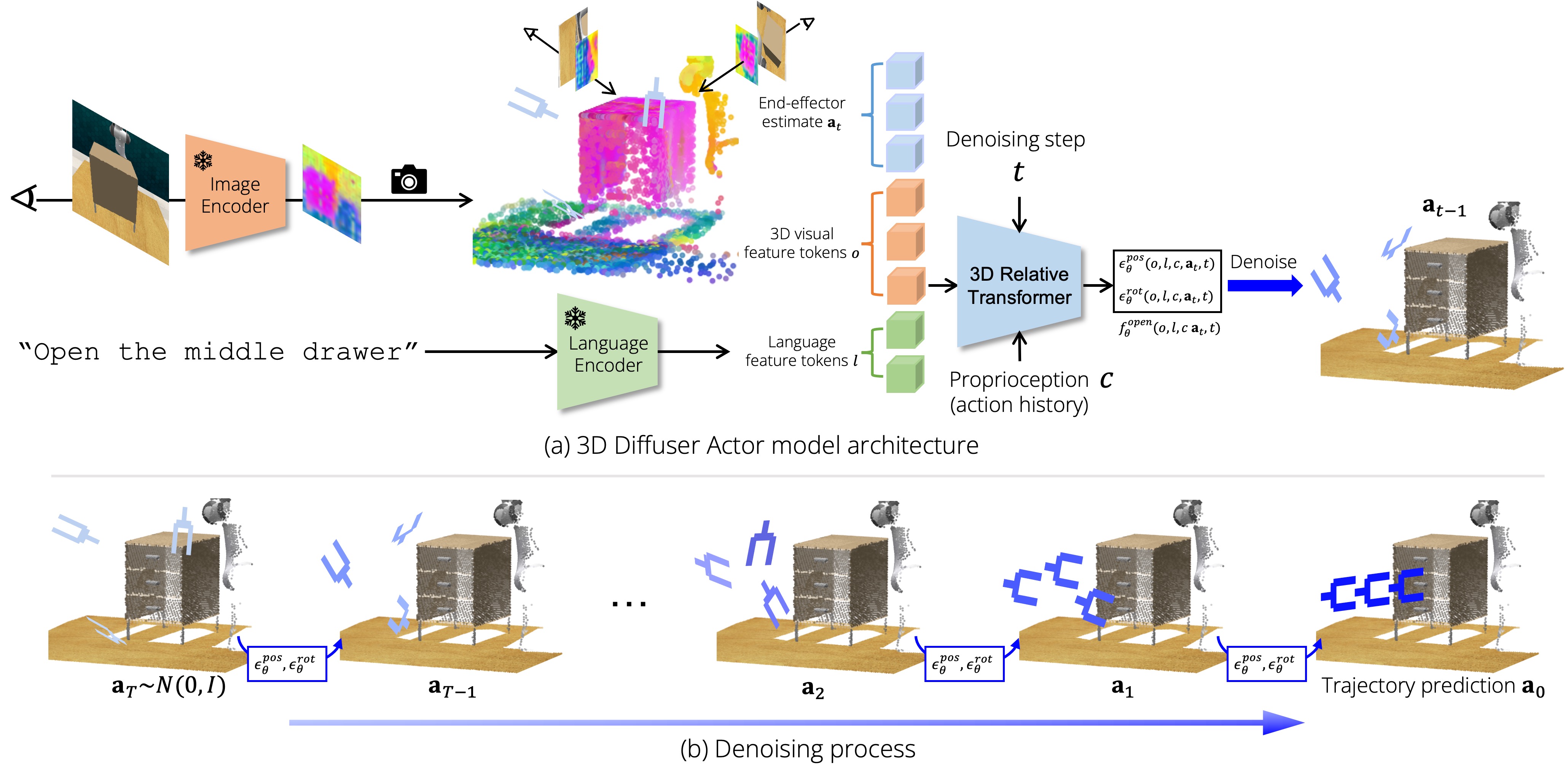
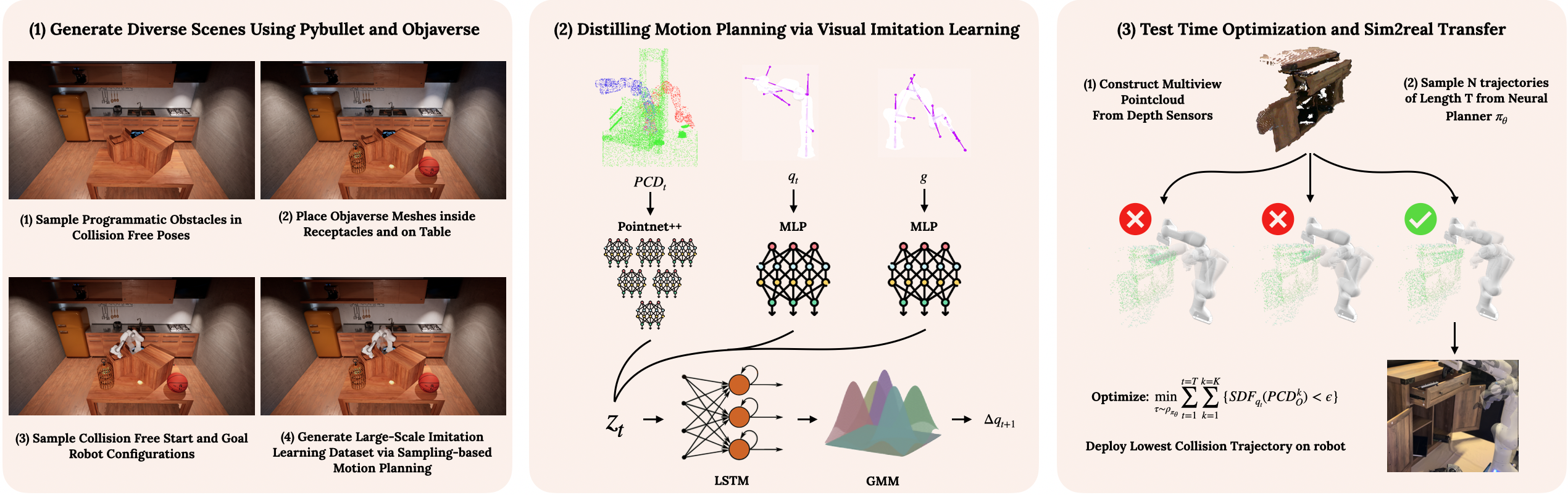
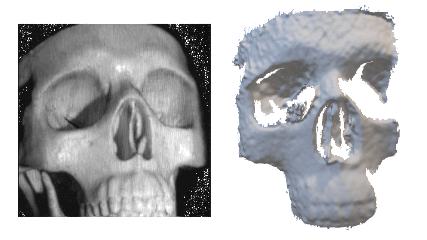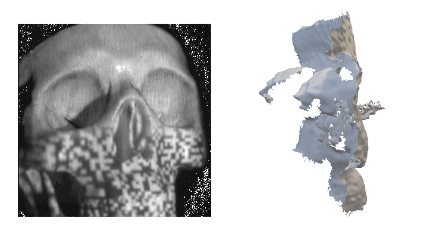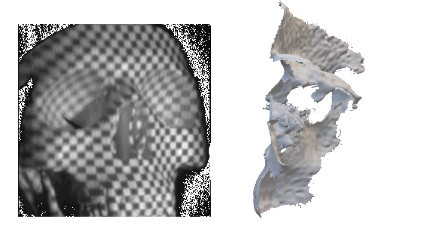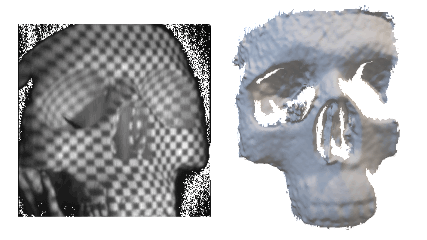
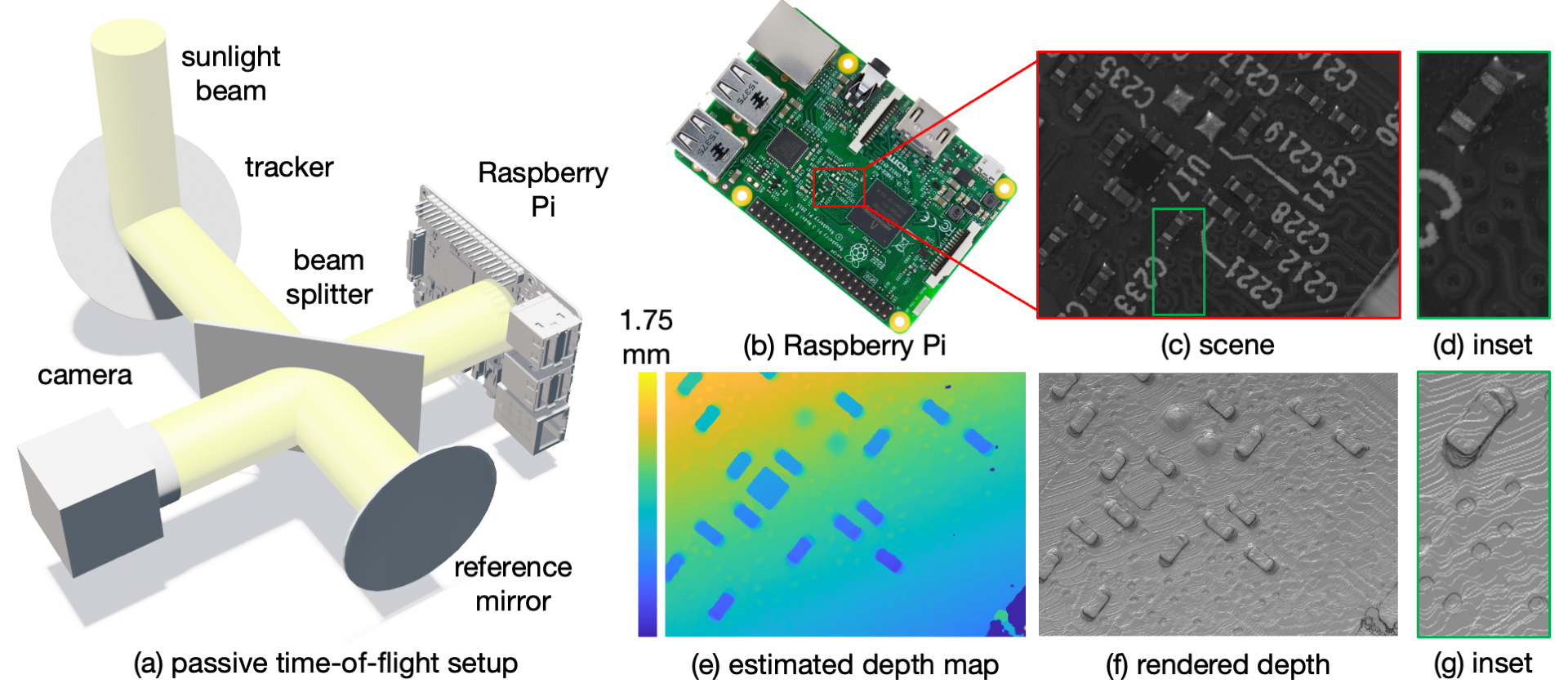
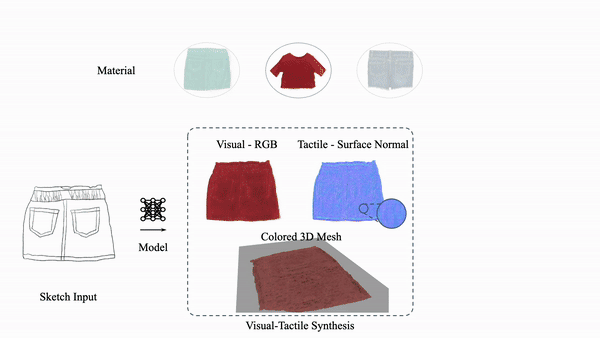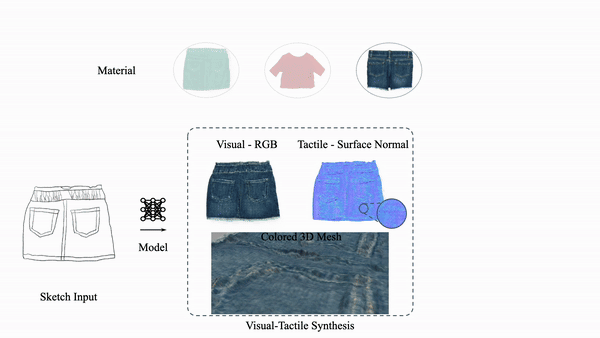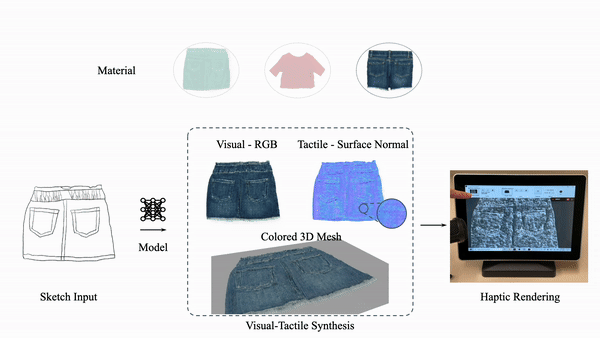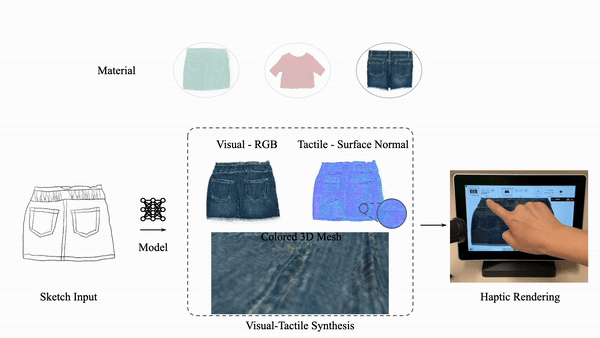
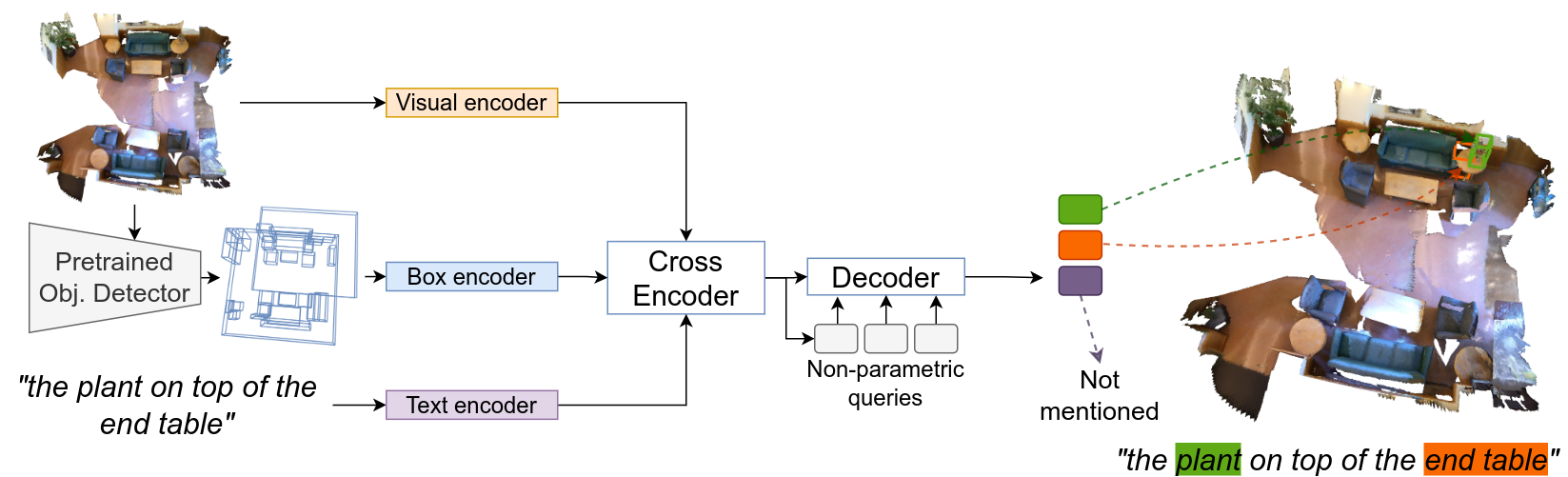
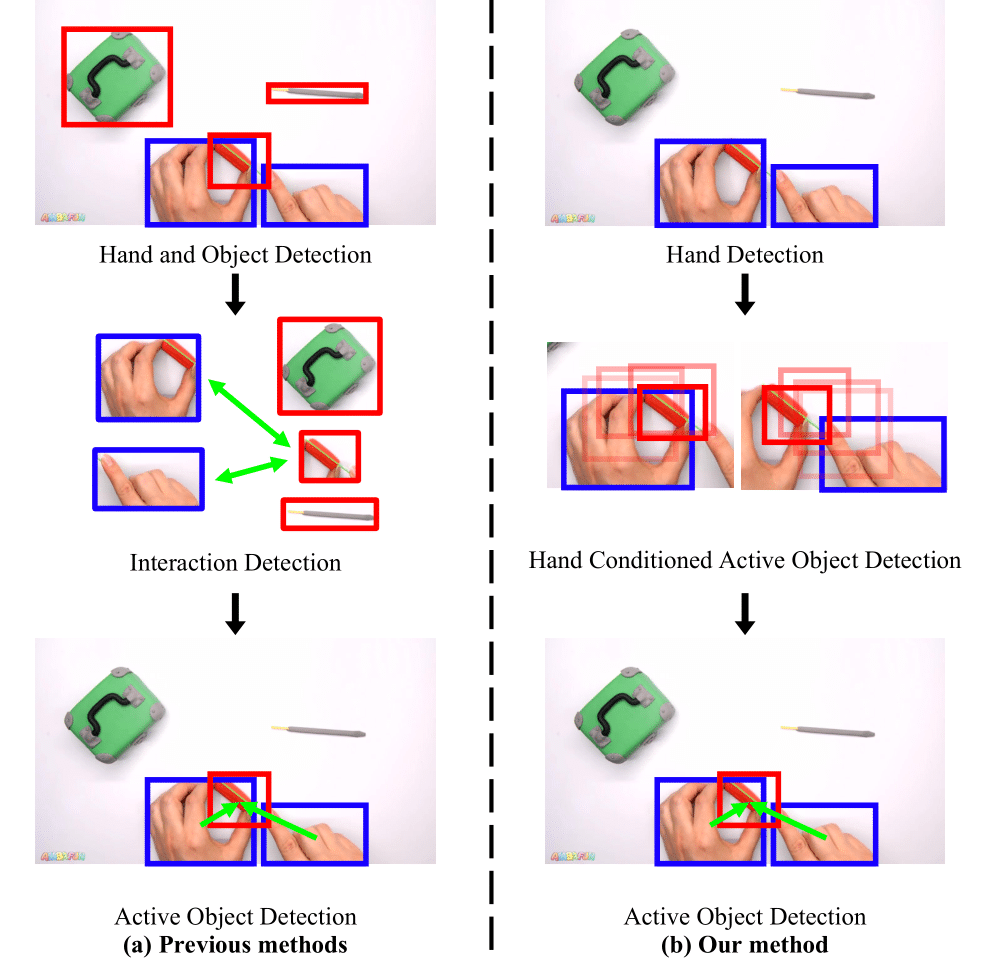
Explore our portfolio of projects spanning 3D vision, generative models, computational imaging, robotics, and more.